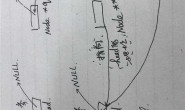
结构体里的指针
struct student *creat()
{
int data;
struct student *pNext;
};
…………
…………
struct student *function()
{
struct student *phead=NULL; //头结点
struct student *pNew,*pEnd; //新节点和尾节点
…………..
…………..
这里开始连接这些节点
if(节点为1个)
{
pNew->pNext=pHead;
pEnd=pNew;
pHead=pNew;
}
else
{
pNew->pNext=pNew;
pEnd->pNext=pNew;
pEnd=pNew;
}
}
就是这一段,,
1:指向符号->和等号有什么区别啊,
2:这些节点是怎么把数据节点连接在一起的啊
表示感觉 很乱,,就是链表,后面的数据结构和这个都有些关联了,,,真在崩溃中,,
解答一下感激不尽
struct student *creat()
{
int data;
struct student *pNext;
};
…………
…………
struct student *function()
{
struct student *phead=NULL; //头结点
struct student *pNew,*pEnd; //新节点和尾节点
…………..
…………..
这里开始连接这些节点
if(节点为1个)
{
pNew->pNext=pHead;
pEnd=pNew;
pHead=pNew;
}
else
{
pNew->pNext=pNew;
pEnd->pNext=pNew;
pEnd=pNew;
}
}
就是这一段,,
1:指向符号->和等号有什么区别啊,
2:这些节点是怎么把数据节点连接在一起的啊
表示感觉 很乱,,就是链表,后面的数据结构和这个都有些关联了,,,真在崩溃中,,
解答一下感激不尽
解决方案
10
假如一个变量本身就是结构体变量,那么对它成员的引用是小数点号。假如这个变量是指针,而它指向的是一个结构体变量,那么对其成员的引用就用箭头->。
等号只是赋值,和结构体成员的引用没关系。
假如结构体成员中的某个指针变量指向了另一个同类结构体变量,那用这个指针就可以找到该变量。
这是指针的使用,建议再看看书。
等号只是赋值,和结构体成员的引用没关系。
假如结构体成员中的某个指针变量指向了另一个同类结构体变量,那用这个指针就可以找到该变量。
这是指针的使用,建议再看看书。
20
1.例如a->pNext = b;
假如->在左边,表示a结点的pNext指针指向b结点(实现了a,b结点的相连)
2.a=b;
相似这样的式子,表示的是将a指针指向b结点
PS:建议题主找个有图的(动态图)理解,会比较容易
http://blog.csdn.net/ggxxkkll/article/details/8661032
假如->在左边,表示a结点的pNext指针指向b结点(实现了a,b结点的相连)
2.a=b;
相似这样的式子,表示的是将a指针指向b结点
PS:建议题主找个有图的(动态图)理解,会比较容易
http://blog.csdn.net/ggxxkkll/article/details/8661032
20
 理解和讨论之前请先学会怎么样观察!
理解和讨论之前请先学会怎么样观察!计算机组成原理→DOS命令→汇编语言→C语言(不包括C++)、代码书写规范→数据结构、编译原理、操作系统→计算机网络、数据库原理、正则表达式→其它语言(包括C++)、架构……
对学习编程者的忠告:
 多用小脑和手,少用大脑、眼睛和嘴,会更快地学会编程!
多用小脑和手,少用大脑、眼睛和嘴,会更快地学会编程!眼过千遍不如手过一遍!
书看千行不如手敲一行!
手敲千行不如单步一行!
单步源代码千行不如单步Debug版对应汇编一行!
单步Debug版对应汇编千行不如单步Release版对应汇编一行!
不会单步Release版对应汇编?在你想单步Release版C/C++代码片断的前面临时加一句DebugBreak();重建全部,然后在IDE中运行。(一般人本人不告诉他!
 )
)VC调试时按Alt+8、Alt+7、Alt+6和Alt+5,打开汇编窗口、堆栈窗口、内存窗口和寄存器窗口看每句C对应的汇编、单步执行并观察相应堆栈、内存和寄存器变化,这样过一遍不就啥都明白了吗。
对VC来说,所谓‘调试时’就是编译连接通过以后,按F10或F11键单步执行一步以后的时候,或在某行按F9设了断点后按F5执行停在该断点处的时候。
(Turbo C或Borland C用Turbo Debugger调试,Linux或Unix下用GDB调试时,看每句C对应的汇编并单步执行观察相应内存和寄存器变化。)
想要从本质上理解C指针,必须学习汇编以及C和汇编的对应关系。
从汇编的角度理解和学习C语言的指针,原本看似复杂的东西就会变得非常简单!
指针即地址。“地址又是啥?”“只能从汇编语言和计算机组成原理的角度去解释了。”
但本人又不得不承认:
有那么些人喜欢或适合用“先具体再抽象”的方法学习和理解复杂事物;
而另一些人喜欢或适合用“先抽象再具体”的方法学习和理解复杂事物。
而本人本人属前者。
不要企图依赖输出指针相关表达式…的值【例如printf(“%p\n”,…);或cout<<…】来理解指针的本质,
而要依赖调试时的反汇编窗口中的C/C++代码【例如void *p=(void *)(…);】及其对应汇编指令以及内存窗口中的内存地址和内存值来理解指针的本质。
这辈子不看内存地址和内存值;只画链表、指针示意图,画堆栈示意图,画各种示意图,甚至本人没画过而只看过书上的图……能从本质上理解指针、理解函数参数传递吗?本人深表怀疑!
这辈子不种麦不收麦不将麦粒拿去磨面;只吃馒头、吃面条、吃面包、……甚至从没看过别人怎么蒸馒头,压面条,烤面包,……能从本质上理解面粉、理解面食吗?本人深表怀疑!
提醒:
“学习用汇编语言写程序”
和
“VC调试(TC或BC用TD调试)时按Alt+8、Alt+7、Alt+6和Alt+5,打开汇编窗口、堆栈窗口、内存窗口和寄存器窗口看每句C对应的汇编、单步执行并观察相应堆栈、内存和寄存器变化,这样过一遍不就啥都明白了吗。
(Linux或Unix下可以在用GDB调试时,看每句C对应的汇编并单步执行观察相应内存和寄存器变化。)
想要从本质上理解C指针,必须学习C和汇编的对应关系。”
不是一回事!
不要迷信书、考题、老师、回帖;
要迷信CPU、编译器、调试器、运行结果。
并请结合“盲人摸太阳”和“驾船出海时一定只带一个指南针。”加以理解。
任何理论、权威、传说、真理、标准、解释、想象、知识……都比不上摆在眼前的事实!
有人说一套做一套,你相信他说的还是相信他做的?
其实严格来说这个世界上古往今来全部人都是说一套做一套,不是吗?
不要写连本人也预测不了结果的代码!
电脑内存或文件内容只是一个一维二进制字节数组及其对应的二进制地址;
人脑才将电脑内存或文件内容中的这个一维二进制字节数组及其对应的二进制地址的某些部分看成是整数、有符号数/无符号数、浮点数、复数、英文字母、阿拉伯数字、中文/韩文/法文……字符/字符串、汇编指令、函数、函数参数、堆、栈、数组、指针、数组指针、指针数组、数组的数组、指针的指针、二维数组、字符点阵、字符笔画的坐标、黑白二值图片、灰度图片、彩色图片、录音、视频、指纹信息、身份证信息……
十字链表交换任意两个节点C源代码(C指针应用终极挑战)http://download.csdn.net/detail/zhao4zhong1/5532495
20
20
所谓数据,就是一个一个的箱子
char 是一个小箱子
short 是一个中箱子
long 是一个大箱子
char * 是一个大箱子
short * 是一个大箱子
long * 是一个大箱子
struct 同样是一个箱子,但是是一个定做的箱子
struct * 是一个大箱子
总的来说,带指针的就是同一规格的大箱子
而不带指针的就是大小不一样的各种箱子
那么区别呢
带指针的箱子规定永远放的只是写有另一个箱子的编号的字条
而不带指针的箱子规定放的就是实际的东西
现在来解析这个结构
typedef struct 定制的超级箱
{
char Fruits[20]; //20个小箱子,存放水果
long toys; //1个大箱子,存放玩具
struct student *pNext; //1个大箱子,存放另一个档案箱的编号字条
}SUPPERBOX;
那么
SUPPERBOX *Head;就是先写好了一个编号字条
new SUPPERBOX;就是制造一个超级箱子;
Head = new SUPPERBOX;就是让这个编号字条和新造的箱子捆绑
剩下的事情就是找东西和放东西,加新箱子和剔除旧箱子
放东西:
Head->Fruits[0]=苹果,
就是找到Head箱子,把苹果放这个箱子的装水果的第一个小箱子里
Head->next->Fruits[0]=苹果,
就是找到Head箱子的装编号的箱子,根据编号找到下一个箱子,把苹果放这个箱子的装水果的第一个小箱子里
[color=#FF0000找东西:[/color]
SUPPERBOX *p=Head; //抄编号
while(p) //假如编号存在,就进行如下操作
{
if(p->toys==小火车) //开玩具箱看,假如是小火车,那么找到
{
//找到了就做爱做的事情
break;//然后走人
}
p=p->next;//没走人说明没找到,那就打开装编码的箱子,抄下一个箱子的编码,继续找
}
[color=#FF0000加新箱子:[/color]
SUPPERBOX *p = new SUPPERBOX; //造一个新箱子
p->next=NULL; //这里放东西,把编号箱先清空
SUPPERBOX *Tail=Head; //抄编号
while(Tail->next) Tail=Tail->next; 找到最后一个箱子Tail;
Tail->next=p; //把新箱子得编号字条放入最后一个箱子的编号箱
[color=#FF0000剔除旧箱子:[/color]
找到要剔除的箱子和上一个箱子
把本箱子的编号箱的字条抄一个替换上一个箱子得编号箱字条
然后把本箱子砸了
char 是一个小箱子
short 是一个中箱子
long 是一个大箱子
char * 是一个大箱子
short * 是一个大箱子
long * 是一个大箱子
struct 同样是一个箱子,但是是一个定做的箱子
struct * 是一个大箱子
总的来说,带指针的就是同一规格的大箱子
而不带指针的就是大小不一样的各种箱子
那么区别呢
带指针的箱子规定永远放的只是写有另一个箱子的编号的字条
而不带指针的箱子规定放的就是实际的东西
现在来解析这个结构
typedef struct 定制的超级箱
{
char Fruits[20]; //20个小箱子,存放水果
long toys; //1个大箱子,存放玩具
struct student *pNext; //1个大箱子,存放另一个档案箱的编号字条
}SUPPERBOX;
那么
SUPPERBOX *Head;就是先写好了一个编号字条
new SUPPERBOX;就是制造一个超级箱子;
Head = new SUPPERBOX;就是让这个编号字条和新造的箱子捆绑
剩下的事情就是找东西和放东西,加新箱子和剔除旧箱子
放东西:
Head->Fruits[0]=苹果,
就是找到Head箱子,把苹果放这个箱子的装水果的第一个小箱子里
Head->next->Fruits[0]=苹果,
就是找到Head箱子的装编号的箱子,根据编号找到下一个箱子,把苹果放这个箱子的装水果的第一个小箱子里
[color=#FF0000找东西:[/color]
SUPPERBOX *p=Head; //抄编号
while(p) //假如编号存在,就进行如下操作
{
if(p->toys==小火车) //开玩具箱看,假如是小火车,那么找到
{
//找到了就做爱做的事情
break;//然后走人
}
p=p->next;//没走人说明没找到,那就打开装编码的箱子,抄下一个箱子的编码,继续找
}
[color=#FF0000加新箱子:[/color]
SUPPERBOX *p = new SUPPERBOX; //造一个新箱子
p->next=NULL; //这里放东西,把编号箱先清空
SUPPERBOX *Tail=Head; //抄编号
while(Tail->next) Tail=Tail->next; 找到最后一个箱子Tail;
Tail->next=p; //把新箱子得编号字条放入最后一个箱子的编号箱
[color=#FF0000剔除旧箱子:[/color]
找到要剔除的箱子和上一个箱子
把本箱子的编号箱的字条抄一个替换上一个箱子得编号箱字条
然后把本箱子砸了